Introduction
Upto now, we’ve seen RAG techniques that i) parse a given document, ii) convert it to text, and iii) embed the text for retrieval. These techniques have been particularly text-heavy. Embedding models expect text in, and parsers break down when provided with documents that aren’t text-dominant. This motivates the question:When was the last time you looked at a document and only saw text?Most business documents, research papers, reports, and presentations we encounter daily are rich visual experiences: tables organizing crucial data, charts illuminating trends, infographics explaining complex concepts, and visual layouts that guide our understanding. These visual elements aren’t just decorative—they’re fundamental to how information is communicated. However, most RAG systems treat these elements as second-class citizens. They are either ignored or captioned and embedded as text. This leads to poor retrieval performance - especially for tasks that require visual reasoning. In this guide, we’ll explore a series of models, starting with ColPali that are built from the ground up to help retrieve images with the same fidelity as text.
What is ColPali?
The core idea behind ColPali is simple: the core bottleneck in retrieval is not the performance of the embedding model, but prior data ingestion pipeline. As a result, this new technique proposes doing away with any data preprocessing - embedding the entire document as a list of images instead.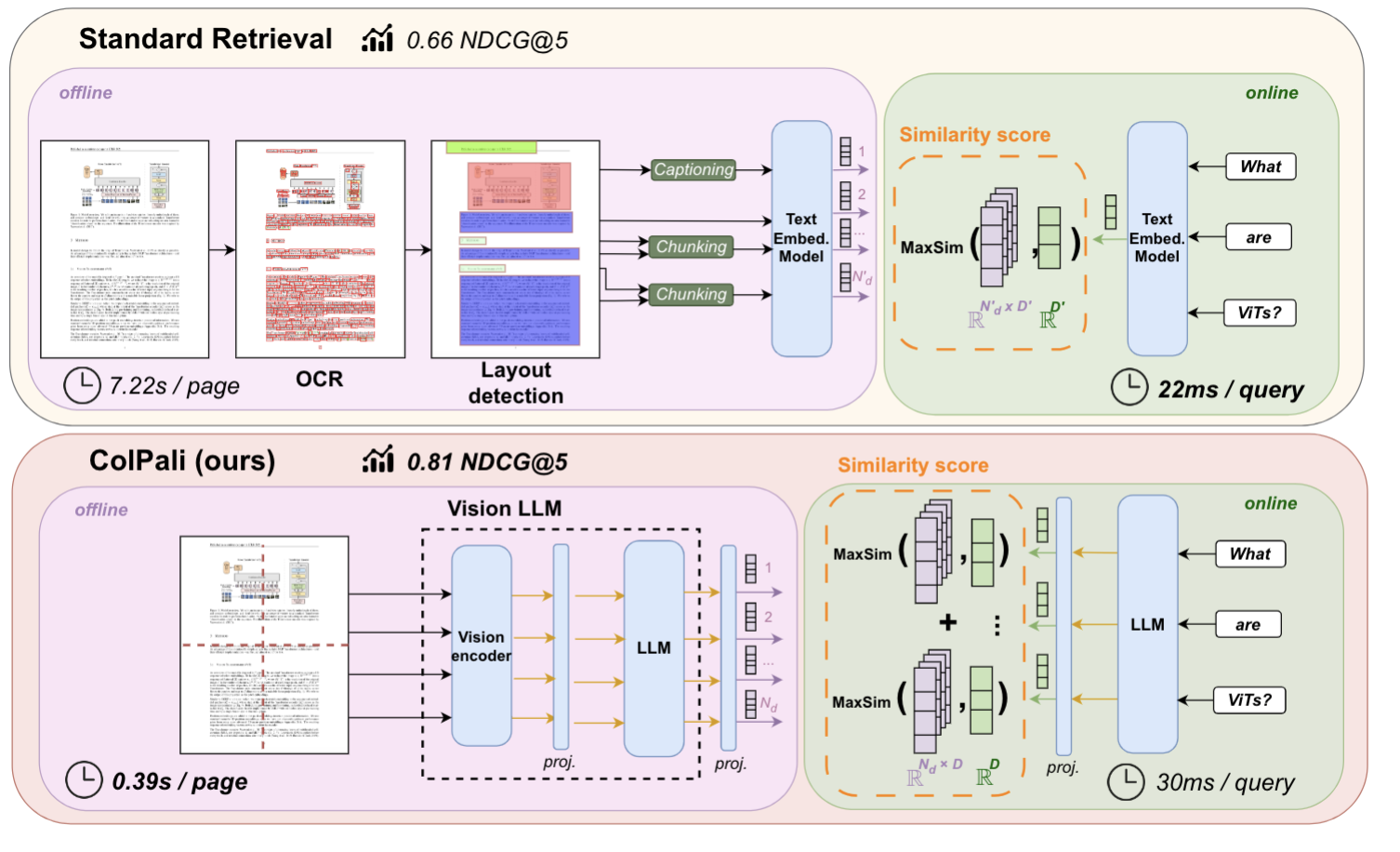
How does it work?
Embedding Process
The embedding process for ColPali borrows heavily from models like CLIP. That is, the vision encoder part of the model (as seen in the diagram above) is trained via a technique called Contrastive Learning. As we’ve discussed in previous explainers, an encoder is a function (usually a neural network or a transformer) that maps a given input to a fixed-length vector. Contrastive learning is a technique that allows us to train two encoders of different input types (such as image and text) to produce vectors in the “same embedding space”. That is, the embedding of the word “dog” would be very close to the embedding of the image of a dog. The way we can achieve this is simple in theory:- Take a large dataset of image and text pairs.
- Pass the image and text through the vision and text encoders respectively.
- Compute the dot product of the image embeddings and text embeddings.
- Penalize the encoders for embeddings that are not close to each other (i.e. a low dot product).
Retrieval Process
The retrieval process for ColPali borrows from late-interaction based reranking techniques such as ColBERT. The idea is that instead of directly embedding an image or an entire block of text, we can embed individual patches or tokens instead. Then, instead of using the regular dot product or the cosine similarity, we can employ a slightly different scoring function. This scoring function looks at the most similar patches and tokens, and then sums those similarities up to obtain a final score.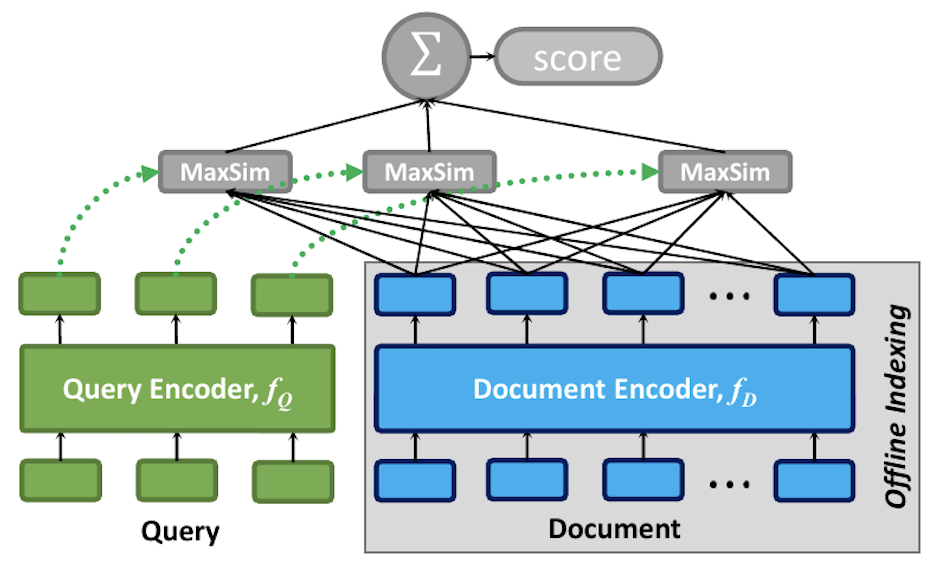
In order to speed up the retrieval process, Morphik uses a technique that computes the hamming distance between individual embeddings instead of the dot product. This is because the hamming distance is a much faster operation than the dot product, and helps scale the retrieval process to millions of documents. This technique is borrows from the amazing team at Vespa.
How to use ColPali?
With Morphik, using ColPali is as simple as adding a singletrue/false parameter to the ingest_file function and the query function. Here is what an example ingestion pathway looks like:
Controlling Output Format
When retrieving ColPali chunks (which are page images), you can control how the images are returned using theoutput_format parameter:
"base64"(default): Returns base64-encoded image data"url": Returns presigned HTTPS URLs, convenient for LLMs and UIs that accept remote image URLs"text": Converts page images to markdown text via OCR
Choosing Between Formats
base64 vs url: Both formats pass images to LLMs for visual understanding and produce similar inference results. However,url is lighter on network transfer since only the URL is sent to your application (the LLM fetches the image directly). This can result in faster response times, especially when working with multiple images.
When to use text: Passing images to LLMs for inference can be slow and consume significant context tokens. Use output_format="text" when:
- You need faster inference speeds
- Your documents are primarily text-based (reports, articles, contracts)
- You’re hitting context length limits
If you’re experiencing context limit issues with image-based retrieval, it may be because images aren’t being passed correctly to the model. See Generating Completions with Retrieved Chunks for examples of properly passing images (both base64 and URLs) to vision-capable models like GPT-4o.